6. 内存模型¶
6.1. 内存空间(Memory Space)¶
TOPS编程模型定义了一个进程中两种不同的内存空间视角,即主机端程序视角、以及核函数视角。从主机端视角来看,内存空间分为两类:主机内存和设备内存。从核函数视角来看,内存空间分为四类:本地内存、共享内存、全局内存和常量内存。
在一个使用GCU芯片进行计算的主机端进程中,主机内存的使用方式和普通进程并无区别。设备端内存的使用则有如下特点:
一个进程可以在多个计算设备上分配设备内存,设备内存和所属计算设备之间存在亲和关系:虽然所有计算设备都可以访问该进程中其他设备的设备内存,但是访问其亲和的设备内存可以获得更高的传输带宽,以及更低的访问延迟。
在TOPS C++中,可以分配设备端全局变量、静态变量或常量,这些设备内存的生命期和所属代码模块的生命期相同
开发者可以调用topsMalloc和topsFree等一系列设备内存管理函数,手动管理当前设备的设备内存
如下图所示,核函数中的内存空间,和其线程模型高度相关。不同层次的线程组,对应不同的内存空间。每个线程拥有自己独享的本地内存,每个线程块拥有各自的共享内存,而整个线程网格中的所有线程,都可以访问全局内存和常量内存。每个核函数的输入和输出,都必须在全局内存中。
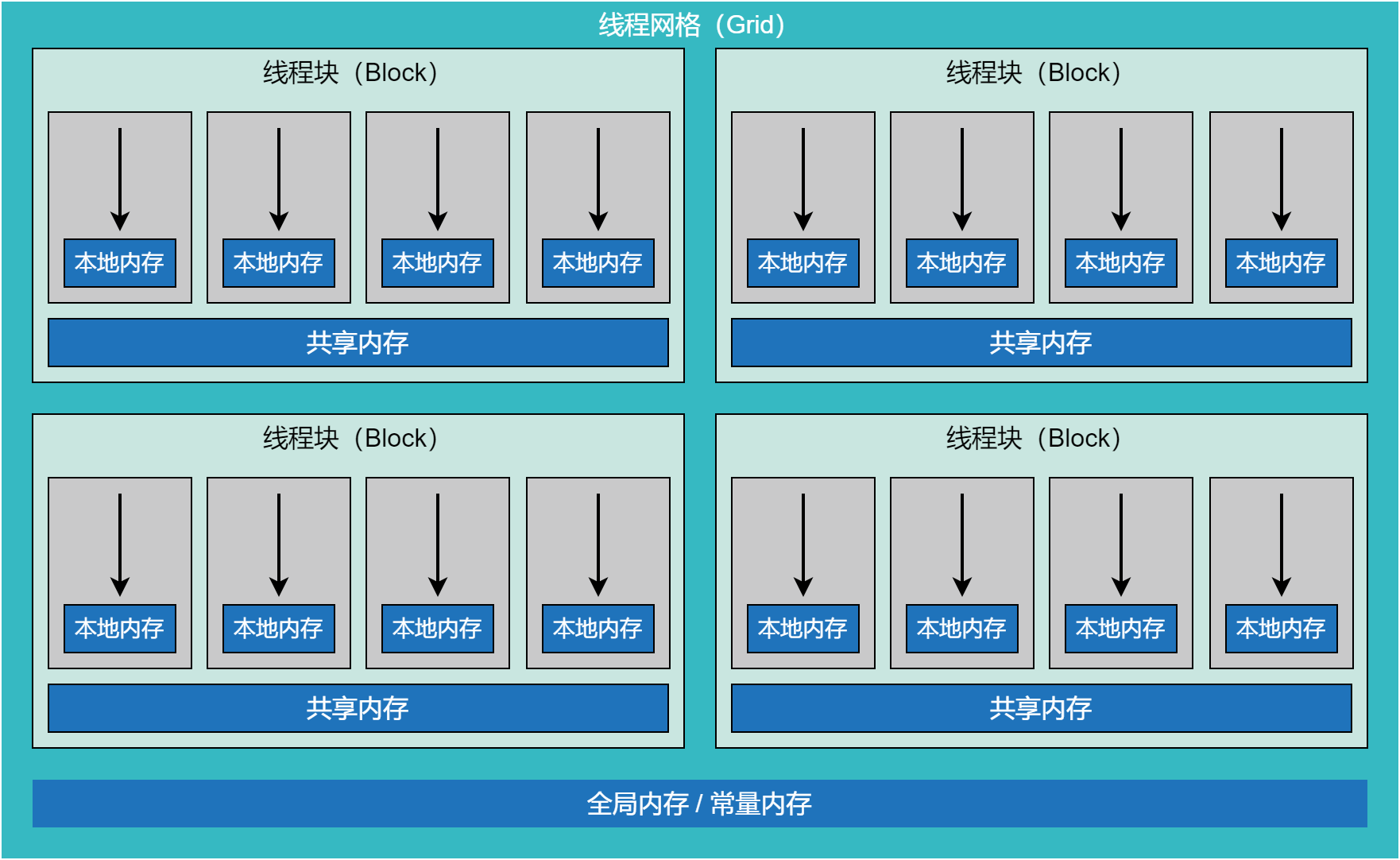
图 6.1.1 核函数视角的内存空间¶
下表中是这四种内存空间的区别:
内存空间 |
可见范围 |
读写限制 |
分配策略 |
生命期 |
|---|---|---|---|---|
本地内存 |
线程独享 |
设备端可读写 |
调度器分配 |
所属线程的生命期内 |
共享内存 |
线程块共享 |
设备端可读写 |
调度器分配 |
所属线程块的生命期内 |
全局内存 |
全局共享 |
主机端和设备端可读写 |
主机端分配 |
超越线程网格的生命期,由主机端程序控制 |
常量内存 |
全局共享 |
主机端可读写、设备端只读 |
主机端分配 |
超越线程网格的生命期,由主机端程序控制 |
内存模型必须明确定义计算单元对内存的可见范围,以便确保程序的正确性。对于可见范围的定义如下:
可见范围 |
定义 |
|---|---|
线程独享 |
仅所属线程可见,每个线程独享自己的本地内存 |
线程块共享 |
线程块内所有线程可见,所有线程共享同一份共享内存 |
全局共享 |
当前进程中的所有线程可见,所有线程访问的是同一份全局内存 |
注意:虽然全局内存常常就是当前设备的设备内存,但这两者并不完全等价。当一个进程中管理多个计算设备时,一个设备上运行的核函数,其访问的全局内存也可以是另一个计算设备上的设备内存。主机内存也可以作为全局内存传递给核函数使用,但这些主机内存需要调用topsHostMalloc分配。
共享内存支持静态共享内存和动态共享内存两种分配方式。详见《C++语言扩展》一章中的`《__shared__》 <#__shared__>`__小节。
6.2. 内存空间的映射(Memory Mapping)¶
不同的内存空间会映射到不同的硬件实现中:
内存空间 |
对应的硬件内存 |
|---|---|
本地内存 |
一级内存 |
共享内存 |
二级内存 |
全局内存 |
设备内存或主机端内存 |
常量内存 |
设备内存或主机端内存 |
主机端和设备端的内存层级和传输通路如下:
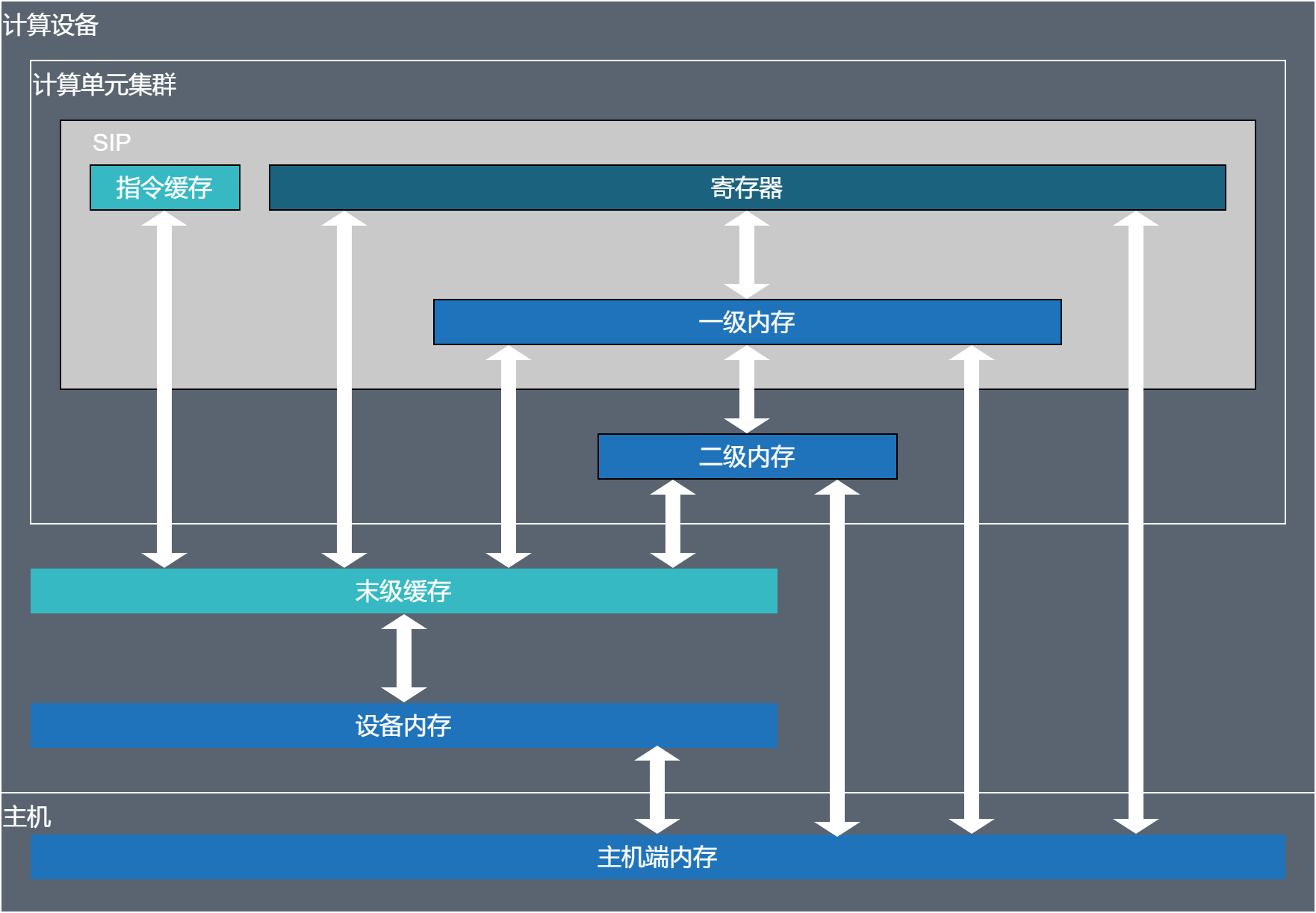
图 6.2.1 内存级别¶
注意:只有GCU300包含末级缓存,而GCU210没有末级缓存。访问某个计算设备的设备内存时,必然会经过其末级缓存。末级缓存对开发者而言几乎是透明的。
6.3. 地址空间(Address Space)¶
当开发者使用指针访问各种内存空间时,指针指向的地址会对应不同的数值,这些数值的分布构成了地址空间。在当前的TOPS编程模型中,主机端程序和核函数分别拥有不同的地址空间。在主机端程序中,主机内存和多个计算设备的设备内存,共享同一个地址空间。在核函数内,则包含如下地址空间:
地址空间 |
内存空间 |
指针长度 |
|---|---|---|
本地地址空间 |
本地内存空间 |
32 bit |
共享地址空间 |
共享内存空间 |
32 bit |
全局地址空间 |
全局内存空间 |
64 bit |
常量地址空间 |
常量内存空间 |
64 bit |
通用地址空间 |
四种内存空间都可以 |
64 bit |
不同的地址空间的地址编码范围不同,因此对应的指针长度也存在差异,可以是32比特,也可以是64比特。
在地址空间中,额外引入了通用地址空间的概念。核函数的形式参数中,如果包含指针,则其可以指向不同的地址空间。为了避免创建多个只有形参指针的地址空间不同,逻辑完全相同的核函数定义,引入了通用地址空间。如此指向本地地址空间、共享地址空间、全局地址空间、常量地址空间的指针,都可以使用通用地址空间指针代替。
6.4. 异步内存分配 (Asynchronous Memory Allocation)¶
异步内存分配器使应用程序能够将设备内存分配和释放与其他在执行流中启动的任务(如核函数启动和异步数据复制)一样,在执行流中进行启动。通过利用执行流的依赖语义重用内存分配,这可以提高应用程序内存的利用率。该分配器还允许应用程序控制分配器的内存缓存行为。当设置适当的释放阈值时,缓存行为可使分配器缓存更大的内存占用而避免与操作系统进行昂贵的系统调用。该分配器还支持在进程之间轻松且安全地共享分配的内存。
对于许多应用程序而言,异步内存分配器减少了对自定义内存管理抽象的需求,并简化了对需要高效自定义内存管理的应用程序的创建。对于已经具有自定义内存分配器的应用程序和库来说,采用异步内存分配器可以使多个库共享由运行时库管理的共享内存池,从而减少过多的内存消耗。此外,运行时库可以根据其对分配器和异步管理接口的了解进行优化。
topsMallocAsync()和topsFreeAsync()是异步内存分配器的核心。topsMallocAsync()返回一个分配的内存块,而 topsFreeAsync()释放一个内存块。这两个接口都接受执行流参数,用于定义内存块何时可用和何时停止可用。topsMallocAsync()返回的指针值是同步确定的,并可用于构建未来的任务。需要注意的是,topsMallocAsync()在确定内存块所在位置时会忽略当前的设备/上下文。相反,topsMallocAsync()根据指定的内存池或提供的执行流来确定内存块所属的设备。最简单的使用模式是将内存块分配、使用和释放都在同一个流中进行。
void *ptr;
size_t size = 512;
topsMallocAsync(&ptr, size, topsStreamPerThread, 0);
// 使用分配的内存块进行计算
kernel<<<..., topsStreamPerThread>>>(ptr, ...);
// 异步释放内存块不会触发CPU和GPU之间的同步
topsFreeAsync(ptr, topsStreamPerThread);
在使用分配的内存块时,如果使用的执行流与分配的执行流不同,开发者必须确保访问发生在分配操作之后,否则行为是未定义的。开发者可以通过主动同步分配的执行流或使用事件在使用的执行流和分配的执行流之间建立依赖。
topsFreeAsync()将释放操作插入执行流中。开发者必须确保释放操作发生在分配操作和对内存块的任何使用之后。此外,在释放操作开始后继续使用内存块会导致行为未定义。应使用事件或执行流的同步操作来确保在释放执行流开始释放操作之前,其他执行流对内存块的任何访问都已完成。
topsMallocAsync(&ptr, size, stream1, 0);
topsEventRecord(event1, stream1);
// stream2必须等待stream1的event1,以确保访问内存块之前已经完成分配。
topsStreamWaitEvent(stream2, event1);
kernel<<<..., stream2>>>(ptr, ...);
topsEventRecord(event2, stream2);
// stream3在释放内存块之前必须等待stream2完成对内存块的使用
topsStreamWaitEvent(stream3, event2);
topsFreeAsync(ptr, stream3);