4. 执行模型¶
下图的TOPS执行模型描述了加速计算平台的硬件拓扑关系抽象。TOPS执行模型由主机端平台(Host Platform) 和多个连接到主机的计算设备(Compute Device) 组成。每个设备包含一个或者多个计算单元(Compute Unit),计算单元中又包含一个或者多个处理单元(Processing Element),处理单元用于实际的并行计算。主机端平台一般是一台服务器,而计算设备是指GCU芯片在主机端操作系统中的PCIe设备。
下图中描述了执行模型中定义的各个组件和它们之间的关系:
主机端程序作为主控,可以同时控制多个计算设备(比如一台机器上的8张卡)
一个计算设备上包含多个计算单元
核函数由调度器调度到不同的计算单元进行大规模的并行计算
所有的计算单元的异步任务之间通过调度器建立和解析任务依赖
所有的计算单元之间可以通过设备内存进行数据交互
主机端程序只能以异步方式启动核函数到计算设备上运行
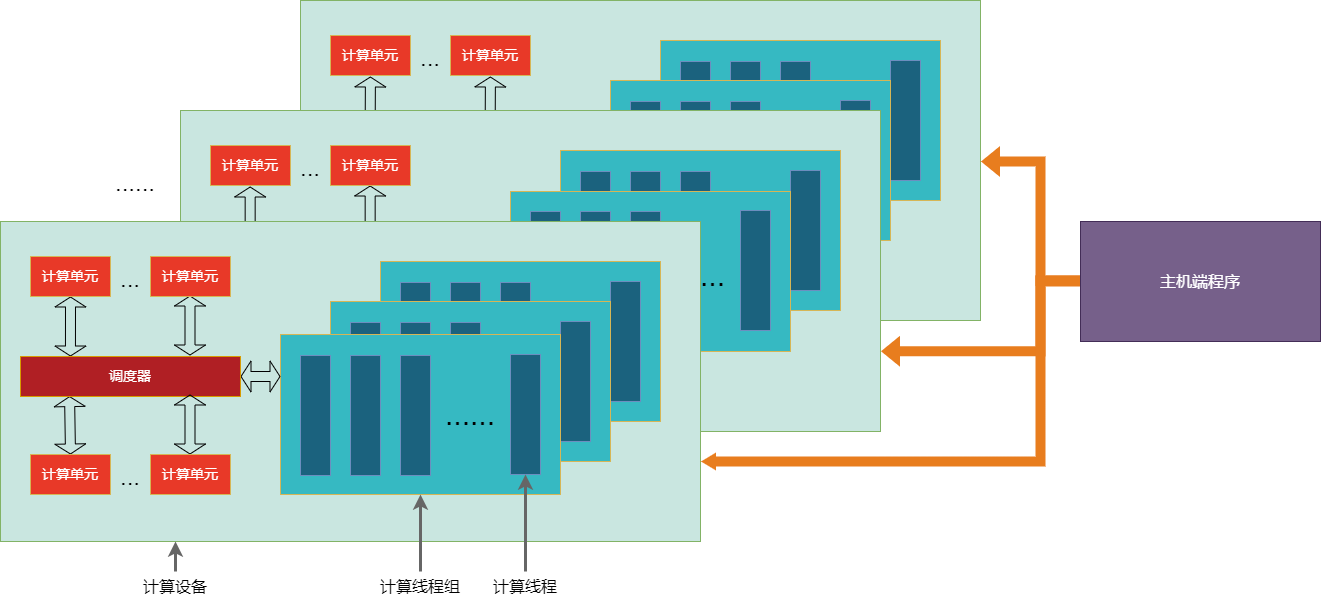
图 4.1 TOPS执行模型¶
TOPS执行模型中定义了两种不同的执行单元:主机端程序(Host Program)和核函数(Kernel Function),分别表示在主机端平台(Host Platform)上运行的程序,和在计算设备上进行并行计算的计算函数。TOPS执行模型的抽象范围限定在一个主机端平台上的一个程序进程内,多个进程和多个主机端平台之间的协作归属分布式计算领域。
主机端程序负责以下任务:
管理一个主机端平台上的多个计算设备
分配、释放计算设备上的设备内存
在主机端平台和计算设备之间传输数据
在计算设备上启动核函数进行计算
核函数负责以下任务:
将计算任务分解、展开为多个计算线程
在多个计算线程之间进行共享、协作和同步
从设备内存上读取输入数据,完成计算后将结果写回设备内存
主机端程序是整个计算任务的主体和入口,在主机端程序中将计算任务分解成若干子任务,将这些子任务分派到不同计算设备的不同计算核心上执行。一般来说,整个分派过程是异步的,并利用执行流(Execution Stream)机制将所有子任务串联成一张有向无环图(Directed Acyclic Graph)。
解决大规模并行计算问题的思路是充分利用计算本身所蕴含的并行性,将这些可以并行的计算拆分到大量的计算节点上同时进行计算,核函数就是为了实现这种拆分而设计的。我们希望每个节点上的计算是可扩展的,不需要感知拆分的数量,这样同一份计算代码,可以应用在不同数量的计算节点上同时并行计算;而不会因为计算节点数量的变化,计算代码就需要重写或者重新编译。这样的一份计算函数就是核函数。
4.1. 主机端程序 (Host Program)¶
主机端程序中的所有机制都是为了启动核函数进行计算服务的,要么是为了启动准备资源和参数,要么是决定启动的顺序和依赖。主机端程序中可以使用C/C++语言,调用主机端运行时库(Host Runtime Library)中所提供的的接口函数来实现以上功能。主机端运行时库的很多接口函数都提供了同步调用与异步调用两个版本,所有的异步调用接口都是基于执行流(Execution Stream)机制来建立依赖的。
开发者定义任务的主入口在主机端程序中,主机端程序中一般按照以下步骤进行计算:
打开指定计算设备或者使用默认计算设备
创建执行流A
在执行流A上分配设备内存
在执行流A上将输入数据从主机端传输到设备内存上
在执行流A上启动核函数1
在执行流A上启动核函数2
在执行流A上将输出数据从设备内存上传输回主机端
在执行流A上释放设备内存
等待执行流A完成执行
销毁执行流A
分配、传输、启动这些接口函数都提供了同步和异步接口,在上述步骤中都使用了异步接口,尽量在计算设备上调用异步接口才能确保达到最高计算性能。每个核函数的输入和输出数据都在设备内存上,在上述步骤中第一个核函数的输出就是第二个核函数的输入,那么在主机端程序中可以连续在执行流中启动两个核函数1和2,然后再等待计算设备完成计算,而不是在每个核函数启动后都在主机端等待计算完成。
主机端程序基于执行流构造异步执行的依赖链,提供了将多种不同的任务异步下发到计算设备上进行处理的能力。执行流是一段指令包(command packet)的序列,会由计算设备按照顺序执行。不同执行流的执行顺序是随机乱序的,可以在多个执行流之间显式的添加依赖来控制它们执行顺序的关系。在主机端同步等待一个执行流,可以确保之前已经下发的所有指令全部完成。每个执行流都会绑定在一个设备上,不能在一个执行流中提交多个设备上的异步任务,但是可以在多个设备上的不同执行流之间建立依赖。
开发者可以创建和销毁执行流。开发者创建的执行流的数量有限制,一旦超过上限会创建失败。
在同一个执行流依次提交的异步执行任务会顺序执行
在不同执行流上先后提交的任务不保证执行顺序,除非在不同执行流之间使用事件(event)机制建立依赖
在不同执行流之间建立的依赖,不可以构成环状,整个基于执行流构建的依赖链必须是一个有向无环图
每个异步任务只能在各自的开始和结束时刻通过执行流和事件机制进行同步,不允许两个异步任务之间存在内部的隐式依赖,否则可能会导致死锁
每个执行流属于一个特定的设备,不可以在一个执行流中提交多个设备上的异步任务
每个事件属于一个特定的执行流,每个执行流属于一个计算设备,因此每个事件间接和一个计算设备绑定
执行流上的记录事件和对应的等待事件必须在同一个计算设备中,如果需要在不同的计算设备间进行事件同步,需要额外调用IPC接口
所有在计算设备上执行的任务,都会提供基于执行流的异步执行接口,也推荐开发者使用这些异步接口
关于执行流的详细内容请参考执行流(Stream)章节。
4.2. 核函数 (Kernel Function)¶
核函数封装了在计算设备上进行大规模并行计算的代码,以及运行这些代码所需要的设备资源。核函数会被展开为多个计算线程,并被调度器调度到多个计算单元上。
核函数在C/C++语言中用以下方式定义:
__global__ void global_kernel_func(int param);
__device__ void device_kernel_func(int param);
核函数定义的时候需要加上__global__或者__device__前缀。只有__global__核函数可以从主机端程序启动,且不能有返回值。__device__核函数只能被其他__global__或者__device__核函数调用,不能从主机端程序启动,可以有返回值。
从主机端调用__global__核函数共有三种方式:
调用topsLaunchKernel启动核函数
调用topsCooperativeLaunchKernel启动核函数
使用
<<<...>>>符号启动核函数,其作用等同于topsLaunchKernel,但是更为方便
// 定义核函数
__global__ void add(float* A, float* B, float* C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main() {
// 使用<<<...>>>启动核函数,其中包含N个线程
add<<<1, N>>>(pA, pB, pC);
}